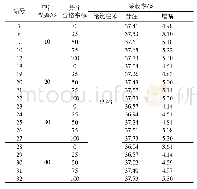
《表1 含沙量的模拟预测结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
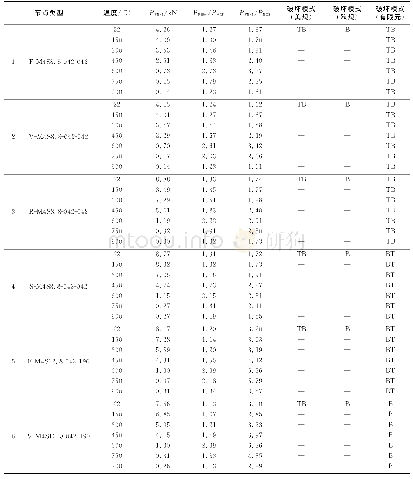
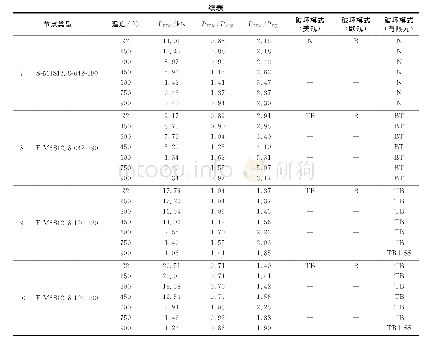
由上表一模拟预测结果可知,采伐量、采伐量、降雨量、年平均流量这四个输入因子对于含沙量的大小有着重要的影响,BP神经网络和ABC-BP在训练样本1961-1976年拟合精度都很高,几乎都达到了100%,但是BP神经网络在预测样本1977-1978年中,相对误差较大,达到了66.57%和41.57%,原因主要为:一是样本数过少,BP神经网络陷入了过拟合状态,二是采用梯度下降法反向传播时,陷入局部最小值。用人工蜂群算法优化后的初始权值、阈值进行训练、预测,精度有了较大的提升,1977-1978年的预测相对误差仅为21.19%和9.80%。同时BP神经网络在预测时由于初始权值的随机化赋值,导致每次预测结果都不一样,确定性很低,而经蜂群算法优化固定后的初始权值、阈值则无此问题。
| 图表编号 | XD00197147700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.15 |
| 作者 | 杨加璐、杨奉广 |
| 绘制单位 | 四川大学水力学与山区河流保护国家重点实验室、四川大学水力学与山区河流保护国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}