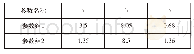
《表2 CNN各层进行运算优化结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
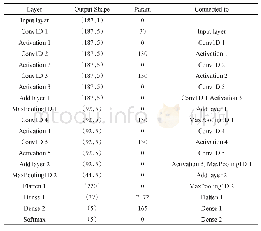
本设计采用300个神经元与8个神经元进行全连接,对于最外层循环,使用“#pragma HLS PIPELINE”指令进行流水线优化,内部循环由系统自动展开,循环展开后能够并行执行8次乘加操作,重叠执行不同循环的循环体能够使用更少的硬件资源来提高整个系统的吞吐量,进一步降低系统计算时延。经过运算优化后的结果如表2所示。
| 图表编号 | XD00188982500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.15 |
| 作者 | 吴进、张伟华、席萌、代巍 |
| 绘制单位 | 西安邮电大学电子工程学院、西安邮电大学电子工程学院、西安邮电大学电子工程学院、西安邮电大学电子工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}