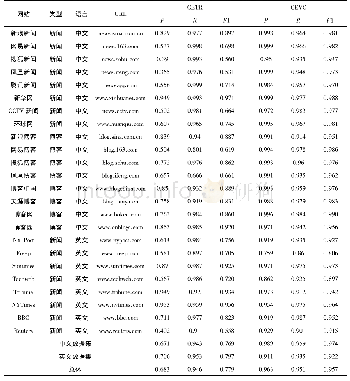
《表1 实验配置:面向Web新闻与博客的内容提取方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
将以上数据来源中的网站形成列表,依次在这些网站中随机收集各50个网页,并通过专家知识对网页主要内容区块进行标记,形成中文与英文数据集,见表1。
| 图表编号 | XD00187018000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 王金麟、方滨兴、于海宁、马雪阳 |
| 绘制单位 | 哈尔滨工业大学计算机科学与技术学院、哈尔滨工业大学计算机科学与技术学院、哈尔滨工业大学计算机科学与技术学院、哈尔滨工业大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}