《表3 不同批次处理样本数目的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
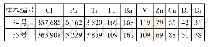
为避免CNN模型陷入局部最优,致使模型泛化能力变差,本实验使用批次处理样本的方式来加快模型的收敛,但批次样本数目过多的话会产生内存消耗及迭代次数过大等问题。本文设置批次样本数为50、100、150、200、300分别进行5次训练,以平均准确率作为评估标准进行模型评估,表3为实验结果。由表中可见当设置批处理样本数目为100时,测试集识别的准确率能够达到最优,因此在本模型中采用批次处理样本数目为100。
| 图表编号 | XD00183561500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.01 |
| 作者 | 闫佳瑛、朱希安 |
| 绘制单位 | 北京信息科技大学信息与通信工程学院、北京信息科技大学信息与通信工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}