《表4 报告及图件总数:地震应急信息自动分类方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
分类标准建成后,以提取的关键词作为自动分类程序中的词库,进行自动分类,流程如图6所示。分类过程中各环节为:(1)将所有格式文档转为.txt格式文件,并输出至原始文件夹;(2)搭建主程序运行环境(Python2.7环境、jieba程序库);(3)运行shell主程序,调用Python子程序模块,将原始文件夹下的所有文件进行分类处理。模块1(cut):获得文件对文件进行分词,并将其存至临时文件夹;模块2(count):对原文件进行词频统计,并对统计结果进行排序;模块3(order):分词词频统计排序前15的词进行排序;模块4(set):根据各类关键词筛选结果,得到关键词库;模块5(classify):将初始文档进行结构化处理后得到的前15词频作为该文档的关键词,将其与关键词库进行对比,通过文档关键词在所划分的5个频率域区间的关键词库匹配率决定文档的归属类别,将文档划分至匹配率最高的类别。判断该关键词属于哪个分类,按照文件归属,把文件归类至该目录下。某个文件可能属于多个类别,如果没有对应的目录,则把文件拷贝至其他文件夹。
| 图表编号 | XD00182264500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 王琳、姜立新、杨天青、张维佳 |
| 绘制单位 | 中国地震局地震预测研究所、中国地震台网中心、中国地震台网中心、中国地震台网中心 |
| 更多格式 | 高清、无水印(增值服务) |


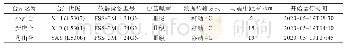



{kind=link}