《表1 勒索软件研究之间的比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
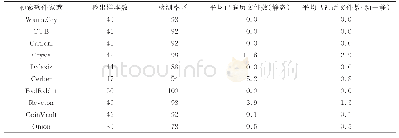
在勒索软件分类的研究中,VINAYAKUMAR[20]等人首次使用动态分析方法对勒索软件进行分类研究。他们将7个勒索家庭和一个良性的软件家族样本进行分类,通过沙箱执行勒索软件得到131个API序列,并将API序列作为特征使用机器学习进行分类,其准确率为98%。但在其实验结果中,分类效果最好的cryptolocker家族和cryptowall家族的真阳性率分别仅为88.9%和83.3%。由于动态分析存在某些缺点,如环境已经被勒索软件进行指纹识别或者反虚拟机识别,勒索研究者提取不到显著的API序列或提取的API序列是无效的。因此,ZHANG[7]等人提出使用操作码的静态方法对勒索软件进行分类,其通过对勒索软件进行反汇编提取出操作码,并将操作码通过n-gram算法处理为不同的n-gram序列,再计算其TF-IDF作为神经网络的输入,从而实现对勒索软件的分类。但实现同样功能的操作码序列并不唯一,因此静态方法不适用于大规模的样本分类。如表1所示,目前较多的研究主要针对勒索软件的检测,而对于勒索软件的分类研究较少且具有一定的缺陷,因此本文引入可视化思想来解决勒索软件分类问题。
| 图表编号 | XD00175828700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.10 |
| 作者 | 郭春、陈长青、申国伟、蒋朝惠 |
| 绘制单位 | 贵州大学计算机科学与技术学院、贵州省公共大数据重点实验室、贵州大学计算机科学与技术学院、贵州省公共大数据重点实验室、贵州大学计算机科学与技术学院、贵州省公共大数据重点实验室、贵州大学计算机科学与技术学院、贵州省公共大数据重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}