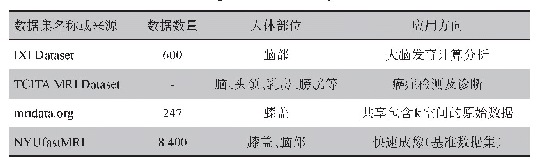
《表1 数据集图像文件的组成》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
前两个压缩文件分别是CNN训练时使用的60 000例图像文件与对应的标签文件;后两个压缩文件分别是测试CNN模型caffemodel.h5时使用的10 000例图像文件与对应的标签文件,图像文件共由5个部分组成,见表1,标签文件由3个部分组成,见表2。
| 图表编号 | XD00170292700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.16 |
| 作者 | 张强、孙静、王威廉、康立富 |
| 绘制单位 | 云南大学信息学院、云南大学信息学院、云南大学信息学院、云南师范大学商学院数据科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}