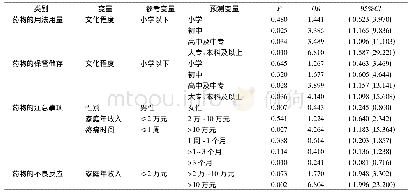
《表2 学习者组群中熟悉度为3、4、5的数据分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《第二语言产出中的日语惯用语回避现象——透明度和熟悉度的影响》
注:p<0.001“***”,p<0.01“**”,p<0.05“*”。表格数据为作者通过构建广义线性混合模型得出。
不难发现,出于本研究的特殊目的,实验中所使用的惯用语皆为对受试者来说较为熟悉的惯用语,因此熟悉度判断的结果分布非常不均匀。在学习者组群中,熟悉度为6的数据点占总数据的57%以上。而母语者组群的偏向性更为突出,熟悉度为6的数据点共占总数据的88%以上。由于后面的数据分析需要构建广义线性混合模型,而大量的数据分布不均将会导致模型构建失败,因此为了解决这个问题,接下来先对学习者组群中熟悉度为3、4、5的数据进行比较(母语者数据过少,因此只分析学习者)。结果表明,在这些数据中,熟悉度和透明度的交互作用并没有发生(如表2所示)。换而言之,熟悉度为3、4、5的数据具有一致性。因此,有理由将熟悉度为3、4的答案归并到熟悉度为5的组群中,在此基础上对熟悉度为5以及熟悉度为6的数据进行比较分析。
| 图表编号 | XD00169055700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.25 |
| 作者 | 陈雯 |
| 绘制单位 | 宁波大学外国语学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}