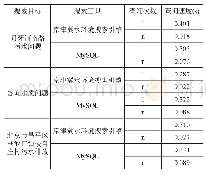
《表8 近似查询处理引擎比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在大数据时代,数据驱动的决策已成为超越竞争对手的主要手段,但计算准确的大规模数据库查询结果的开销极其昂贵。因此,能够有效进行近似计算且具有高准确性的查询方法具有很高的研究价值。传统的近似查询处理研究大多基于采样方法,在查询执行过程中对数据进行动态采样,以回答近似问题,或根据查询负载预测,对表和列进行线下采样,保存在内存中,处理查询任务。虽然传统的近似查询处理算法能基本处理近似查询问题,但存在以下三个明显缺陷:第一,错误率高、内存开销大;第二,算法无法支持许多重要的数据分析任务;第三,较低的查询响应时间,传统的算法要求在大型数据分析集群上执行并行查询,但集群的获取和使用的成本很高。针对以上问题,近期人工智能赋能的近似查询处理引擎研究相关文献比较如表8所示。
| 图表编号 | XD00165382900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 宋雨萌、谷峪、李芳芳、于戈 |
| 绘制单位 | 东北大学计算机科学与工程学院、东北大学计算机科学与工程学院、东北大学计算机科学与工程学院、东北大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}