《表2 两组实验数据表:结构化数据的隐私与数据效用度量模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
政务数据包含了大量的个人信息,非常具有挖掘价值,但政务数据包含的敏感数据太多,导致政务部门不敢发布数据,采取的是与数据接收机构签约合作的方式进行数据共享。隐私与数据效用的度量能够使数据发布者有效把握发布数据的隐私和数据的可用性,对评估隐私泄露风险有重要的意义。为了体现实验的准确性和科学性,采用公开的UCI机器学习数据库中的adult数据来完成实验分析,该数据包含了48 842条记录和14项属性。下面选取包含年龄(age)、学历(education)和职业(occupation)属性的前5条记录作为实验室数据集D1,并在D1的基础上进行简单的修改作为实验数据集D2(表2),数据集D2用于与数据集D1的隐私量进行对比分析,并用差分隐私对数据集D1进行保护来对度量模型进行分析,分析数据的隐私量、带隐私偏好数据的隐私量、数据效用和隐私保护程度。
| 图表编号 | XD00163337000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 谢明明、彭长根、吴睿雪、丁红发、刘波涛 |
| 绘制单位 | 贵州大学数学与统计学院、贵州大学贵州省公共大数据重点实验室、贵州大学贵州省公共大数据重点实验室、贵州大学计算机科学与技术学院、贵州大学计算机科学与技术学院、贵州大学密码学与数据安全研究所、贵州大学数学与统计学院、贵州大学贵州省公共大数据重点实验室、贵州大学贵州省公共大数据重点实验室、贵州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |


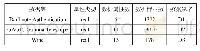



{kind=link}