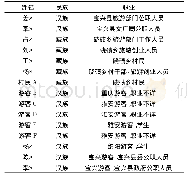
《表1 非数值化数据集结构》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《非数值化特征的条件概率区域划分(CZT)编码方法》
数据集特征有〈特征1,特征2,…,特征K〉,相应的数据集结构如表1所示。为了简化表述,所考虑数据均为非数值化特征,各维特征的非数值化取值空间分别为〈S1,S2,…,SK〉,且每个取值空间具有元素个数分别为〈s1,s2,…,sK〉,即si|Si|,i=1,2,…,K,可记Si={F1,F2,…,Fsi},i=1,2,…,K,即实际数据中属性i的取值为fi,°∈Si。虽然特征的取值是非数值化的,仍然可以用实数刻画,不妨设F°∈R。例如,投掷立方体的取值空间是立方体的六个平面,但仍然可以将其标记为实数,只是这时的具体数值没有实数意义,即不能表明标记为1的平面与标记为6的平面有任何数值上1与6的关系,对这样的实验求期望也是没有意义的,然而深度学习方法较强的学习能力可能会学习到这一类关系。另一方面,还可以认为F°是特征事件集合到实数R的泛函,即对相应特征取值的实数映射。对于特征i,取值为fi,j=Fj∈Si记为事件ωj,该特征的全部事件记为Ωi,可以构造随机变量Xi(ωj)=Fj,即对每一维特征i,都可以看成是一个随机变量,本文直接用Xi表示特征i。对于非数值化特征的问题,随机变量是离散的,下面讨论的问题均以概率形式出现,涉及概率密度概念时,如无特殊说明,指该随机变量取值空间稠密但可以无一致连续要求的情况下近似的概率密度曲线,此时概率密度为函数微元。
| 图表编号 | XD00163334300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 贺亮、徐正国、李赟、沈超 |
| 绘制单位 | 盲信号处理重点实验室、盲信号处理重点实验室、盲信号处理重点实验室、西安交通大学智能网络与网络安全教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}