《表2 边缘检测方法及其数据测量》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
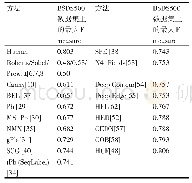
我们列出了表2中代表性方法的最大F-measure。从表中可以发现,传统基于梯度的边缘检测算子Roberts、Sobel、Prewitt在BSDS300数据集上实现的F-measure值约为0.48,Canny边缘检测的F-measure为0.58。而通过基于统计学习的方法,F-measure从0.63变化到0.74。通过gPb[31]和SCG[40]获得具有灰度信息的最高F-measure值为0.74。根据BEL[37],gPb[31]和SCG[40]提供的经验评估及颜色信息的整合将F-measure值提升约0.02~0.03。基于tPb边缘响应预测和基于顺序标记的边缘链接,在BSDS500数据集上的最高F-measure值为0.74[34]。此外,SFE算法的BSDS500数据集的最高F-measure值为0.74[38]。因此,基于统计学习的边界检测比基于差异化的边缘检测更加精确。除了测量精度,计算效率也是评估的一个关键问题。在所有基于学习的方法中,只有SFE[38]是实时的。BEL[37]和SFE[38]是基于通用描述符和特征选择分类算法(即用于BEL的Boosting和用于SFE的随机森林),它们具有相对低的计算成本,但该算法不适用于基于稀疏码计算的SCG[40]。SFE是计算成本最高的方法[38],其全局信息和边缘链接的整合虽然增加了F-measure值,但计算时间也增加了。
| 图表编号 | XD00163293100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.20 |
| 作者 | 张岩、赵玉涛、李光旭、郑洲洲、张森 |
| 绘制单位 | 青岛科技大学机电工程学院、青岛科技大学机电工程学院、青岛科技大学机电工程学院、青岛科技大学机电工程学院、青岛科技大学机电工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}