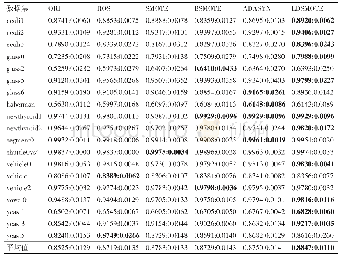
《表1 过采样前后训练集正样本比例n(%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
近年来,不平衡学习问题作为机器学习的研究领域之一得到密切关注,其本质是数据分布不均衡,导致很多机器学习分类算法的性能被削弱。机器学习算法在不平衡数据集上训练时,倾向于将样本预测为多数类。尽管如此可以得到较高的准确率,但会导致很低的召回率,从而出现预测模型无法将正样本准确分类的情况,甚至造成预测模型完全失效。数据不平衡问题广泛存在于机器学习的各个领域。相对于多数类样本,少数类样本通常携带更为重要的信息,具有更高的错判代价。因此,多数情况下,我们应当更加关注少数类样本的分类准确性。要处理样本不平衡问题,通常是从数据、算法和集成三方面着手。数据层面的方法通常为上采样、下采样和混合采样[21-22]。就医学数据而言,很多数据集都是不平衡样本,正负样本比例差异较大,敏感性、特异性差异较大,导致模型的鲁棒性较差,而心电数据往往存在样本数量不平衡问题[2]。本研究存在样本不均衡问题,所有分类中正样本比例均显著低于负样本比例。欠采样使最终的训练集丢失部分数据;而过采样会导致一个数据点在高维空间中出现多次,增加过拟合风险,很多研究通过在过采样中加入少量随机噪声来减少这类风险。本文基于心电图多导程特点,利用过采样方法采集不同的心电导程,如图8中加粗部分所示。由于心电采集过程中背景噪音的存在,不会出现完全一致的数据点,因此避免了上述简单复制所带来的问题。表1为训练集过采样前后的正样本比例数据,经过采样后,训练集正负样本比例大致相同。
| 图表编号 | XD00155540600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.28 |
| 作者 | 王官军、吴婷、汪龙、唐祖胜 |
| 绘制单位 | 十堰市太和医院全科医学科、十堰市太和医院循证医学中心、十堰市太和医院全科医学科 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}