《表2 特征权重计算结果:基于ReliefF与互信息结合的特征评价、筛选的家庭负荷类型辨识方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于ReliefF与互信息结合的特征评价、筛选的家庭负荷类型辨识方法研究》
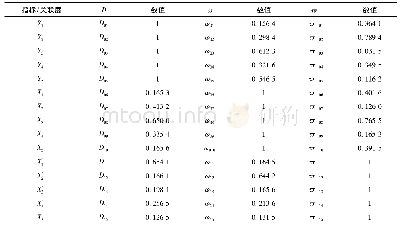
式中R1[A]表示样本R1在特征A上的值,diff(·)表达了各样本之间特征的距离大小。式(1)中H表示同类型样本,M表示不同类型样本。P(C)表示第C类样本占总样本数的比例。K表示近邻样本数,m表示抽样次数。由式(1)可知,ReliefF权重计算体现了聚类的思想,W(A)的取值表达了样本特征量的类间距离与类内距离之差。当样本特征间类间距离足够大、类内距离足够小时,该特征对分类目标的贡献度就越大,其权重取值也就越高。对16个特征的权重计算结果如下表2所示:
| 图表编号 | XD00148608800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.25 |
| 作者 | 薛冰、温克欢、李伟华、张之涵、唐义锋 |
| 绘制单位 | 深圳供电局有限公司、深圳供电局有限公司、深圳供电局有限公司、深圳供电局有限公司、深圳深宝电器仪表有限公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}