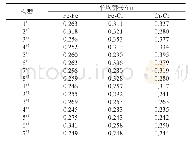
《表2 集群配置Tab.2 Cluster configuration》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Spark框架的能源互联网电力能源大数据清洗模型》
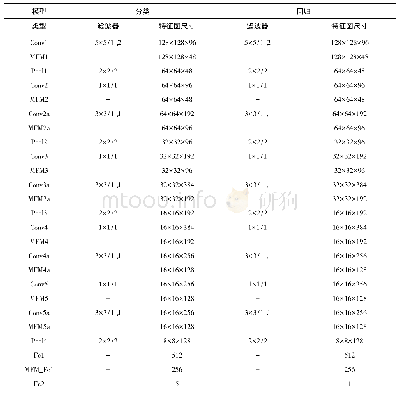
本文采用“Spark On Yarn”集群模式构建能源大数据清洗模型实验环境,实验采用6台服务器组成数据清洗集群节点,其中一个节点为Master,其余五个节点分别为Slave1-Slave5,每个节点的配置如表2所示。每个服务器节点采用Ubuntu-12.04.1操作系统,使用Hadoop-2.6.0,Spark-1.3.1,Scala-2.10.5,JDK-1.7.0_79搭建节点的软件环境。实验平台在Scala的Intellij Idea开发环境上进行开发实现,以hadoop的hdfs实现数据结果的存储。
| 图表编号 | XD0014197100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.01.25 |
| 作者 | 曲朝阳、张艺竞、王永文、赵莹 |
| 绘制单位 | 东北电力大学信息工程学院、东北电力大学信息工程学院、东北电力大学信息工程学院、东北电力大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}