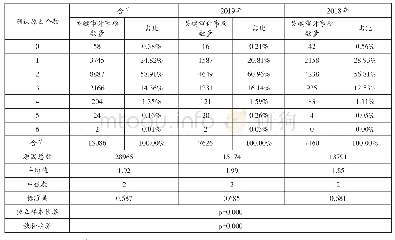
《表1 情绪原因数量的分布情况》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
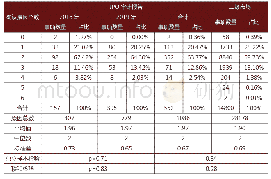
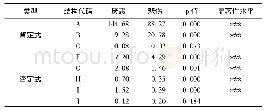
目前,仍然缺少情绪原因检测的中文微博数据集。对于中文微博的情绪原因检测,大都是研究人员各自构建数据集。文献[6]针对表述规范的文本,公开了基于新闻文本构建的情绪原因检测数据集,弥补了之前没有公开数据集的空白,进而推进了情绪原因检测任务的发展。目前,该数据集已经成为情绪原因检测任务的基准数据集。该数据集包含了喜(Happiness)、悲(Sadness)、惧(Fear)、怒(Anger)、恶(Disgust)、惊(Surprise)六种情绪[6];包含2105篇文档,11799个子句,其中包括2167个情绪原因子句,情绪原因数量的分布情况如表1;原因子句与情绪表达子句的距离分布如表2,“0”表示原因子句与情绪表达在同一子句,“-”表示原因子句在情绪表达子句左边,“+”表示原因子句在情绪表达子句右边,经过分析可发现大部分情绪原因子句在情绪表达子句的前一个子句或者同一子句。
| 图表编号 | XD00140374600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.25 |
| 作者 | 陈珊珊、姚攀 |
| 绘制单位 | 四川大学计算机学院、四川大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}