《表3 原始数据与各方法填补后数据的相关性》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
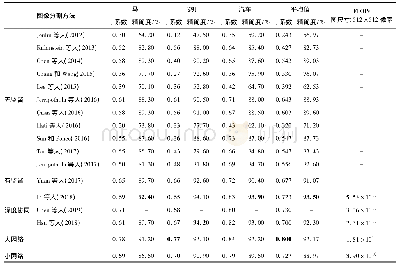
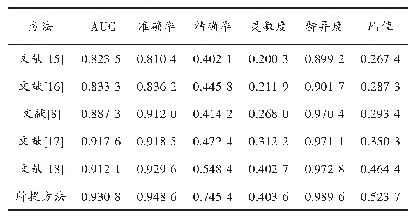
通过对2920组数据进行分类分属性的统计分析,发现不同属性的数据都存在着不同程度的缺失,数据分属性缺失程度如表2所示。分析表中数据可以发现,各个设备能耗的缺失数据数量相差并不大。为了数据挖掘结果的精确性,需要对这些缺失数据在预处理阶段进行填充。在SPSS软件中利用替换缺失值对缺失数据进行替换,填补方法包括序列平均值、临近点的中间值、临近点的平均值、线性插值、邻近点的线性趋势。不同的数据类型采用不同的方法,填补误差也不同,为了尽量减少填补误差,选取了北热泵机组运行的一月份数据随机删除部分数据,分别采用这几种方法进行缺失值的填补并得到数据曲线,如图2所示,可以发现序列平均值的填补效果最差,主要是由于该数据是电量的累计值,序列平均值是将整个序列数之和的平均数,填补到序列中会与前后值存在着明显的差异。而剩余的其他方法利用所得的数据曲线分辨不出填补效果,采用Person相关系数法将利用其他方法得到的数据与原始数据进行相关系分析,得到的相关系数结果如表3所示。
| 图表编号 | XD00135710500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.17 |
| 作者 | 陈鑫、单明珠 |
| 绘制单位 | 山东建筑大学 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}