《表2 不同像素块大小的对比(%)》
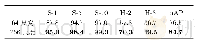 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
ICDAR2013[3]标准数据集的训练集和测试集分别包含了100和250个书写者的笔迹材料,每个书写者贡献4张笔迹材料,其中2张的笔迹内容为英语,另外两张为希腊语.由于混合语言,这个数据集的笔迹识别具有较大的挑战.对数据集分别进行64与256尺度的像素切割之后,64尺度切割的小像素块数量为:训练集70 911个,测试集218 999个;256尺度切割的小像素块数量为:训练集21 160个,测试集64 820个.我们分别对这两个尺度切割的数据进行了实验,结果如表2所示.结果显示:基于词级别大小数据提取的特征比基于字母级别大小数据提取的特征,在所有的指标上均取得更好的表现,表明基于词级别大小的数据更适合于DLS-CNN,因为基于词级别大小的数据包含更多的完整笔迹.并且,256尺度切割的像素块比64尺度切割的像素块少,使得模型在256尺度的数据上进行实验的运行时间相对较短.为此,接下来的所有实验均基于256尺度切割的数据.
| 图表编号 | XD00135238900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 陈使明、王以松 |
| 绘制单位 | 贵州大学计算机科学与技术学院、贵州大学计算机科学与技术学院、贵州省智能医学影像分析与精准诊断重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}