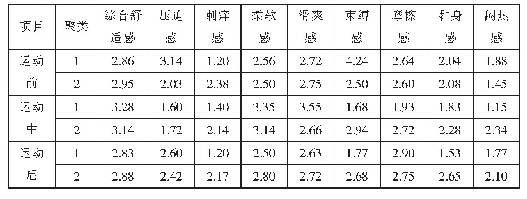
《表1 最终的聚类结果(标准化后)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
数据预处理后,根据本次数据挖掘的需求,采用K-means聚类算法对客户进行分群,群的数量可结合实际需求自行设定。K-means聚类算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的类数K(本次将K设置为3),采用距离作为相似度的评价指标,认为两个对象的距离越近,其相似度就越大,将其划分在同一个类别中。为了得到更好的聚类结果,将聚类过程迭代次数设置为500。如表1所示。
| 图表编号 | XD00126442100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.10 |
| 作者 | 徐伶伶、张淑莲、张欣 |
| 绘制单位 | 青岛工学院、青岛工学院、青岛工学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}