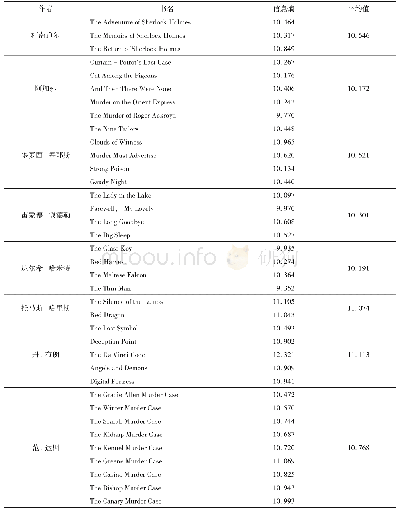
《表1 部分背景词:一种基于词聚类信息熵的新闻提取方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在对正文进行分析前,需要首先对语料进行一系列的分词、去停用词等预处理操作。其中,分词使用了Pkuseg工具[18]的新闻领域模型,去停用词采用了停用词典的方式。此外,在预处理阶段还进行了背景词的去除。实验语料围绕“一带一路”这一主题展开,具有一定的特殊性。因此,文本的高频词中存在大量背景词,即在所有文章中都频繁出现,但对文章区分度并不大的词汇[19],这些背景词无法满足利用历史高频词发现新话题文章的需求。因此,本实验剔除了语料中对于新话题文章提取造成干扰的背景词,将剔除背景词后的历史高频词作为计算信息熵的随机事件。表1中列出了语料中的部分背景词。
| 图表编号 | XD00122256200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.15 |
| 作者 | 牛伟农、吴林、于水源 |
| 绘制单位 | 中国传媒大学智能融媒体教育部重点实验室、中国传媒大学智能融媒体教育部重点实验室、中国传媒大学智能融媒体教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}