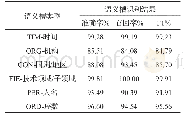
《表6 序列标注模型识别语义槽效果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在语义槽填充器环节,研究选取150000个句子作为序列标注模型训练过程的数据集,采用Python-crfsuite进行模型训练,序列特征选取上下文特征,训练算法为L-BFGS,采用Elastic Net(L1+L2)进行正则化,L1惩罚系数1.0,L2惩罚系数0.001。训练迭代次数为100轮。表6展示了在测试集上的语义槽要素识别结果。从中可以看出,模型具有较高的准确率和召回率,能够用于问答系统的语义槽识别。
| 图表编号 | XD00121902900 严禁用于非法目的 |
|---|---|
| 绘制时间 | |
| 作者 | 吕璐成、韩涛、王燕鹏 |
| 绘制单位 | 中国科学院文献情报中心、中国科学院大学经济与管理学院图书情报与档案管理系、中国科学院文献情报中心、中国科学院大学经济与管理学院图书情报与档案管理系、中国科学院文献情报中心 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}