《表3 匹配平衡性检验———匹配前后的样本特征对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:*、**、***分别表示在10%、5%、1%的显著性水平。
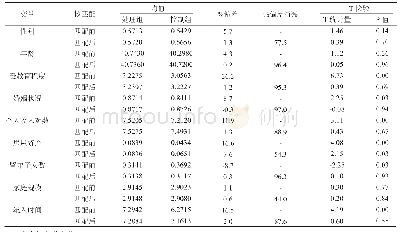
基于PSM方法,在对实验组和控制组进行匹配的过程中,首先通过战略性新兴产业政策(POL)对解释变量做一个初步的LOGIT回归,然后对LOGIT模型进行逐步回归,筛选出对被解释变量(POL)有显著影响的解释变量企业规模Size)、企业年龄(Age)、资本密集度(K)、资产收益率(Roa)、资产负债率(Lev)、企业固定资产规模(PPE)、流动比率(Liquidity)并获得倾向得分值。再根据筛选出的变量,提取实验组在营改增实施前一年的样本,将该样本继续与控制组逐一匹配并检验实验组与控制组各项变量的显著偏差,再根据偏差的绝对值范围定义匹配效果,若偏差的绝对值超过10%,则说明匹配后的各项变量偏差较大,匹配效果不理想;反之若偏差的绝对值小于10%,则说明匹配后的各项变量偏差较小,匹配效果理想。本文的PSM匹配的检验结果如表3所示。据表可知,实验组和控制组在倾向得分匹配后,变量Size、Age、K、Roa、Lev、PPE、Liquidity的平均值偏差的绝对值都小于10%,且t值显示差异也不显著,说明以上变量在实验组和控制组中是分布均衡的,满足计量统计意义上的同质性要求,且同时符合DID方法使用的基本假设条件,由此可知本文使用PSM-DID模型是可行的。
| 图表编号 | XD00120628000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.20 |
| 作者 | 陈文俊、彭有为、胡心怡 |
| 绘制单位 | 桂林理工大学、中南林业科技大学、中南林业科技大学、中南林业科技大学 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}