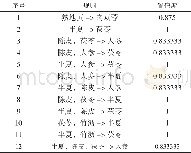
《表4 支持度最高的5条规则》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
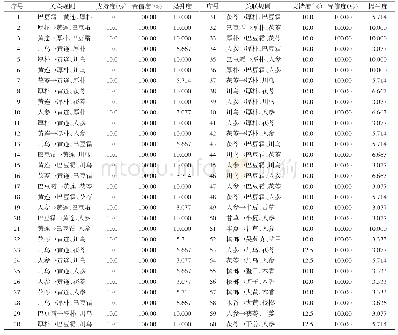
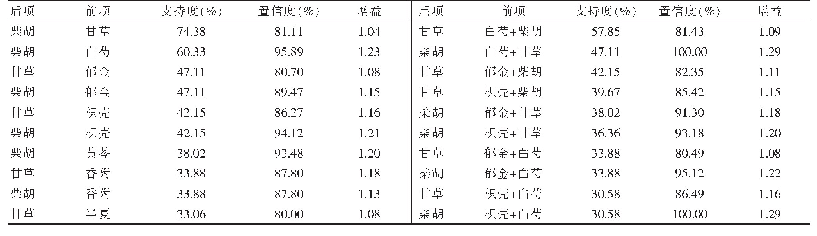
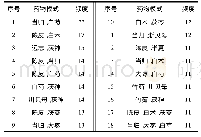
本文专利文本关联规则挖掘的实验在R语言环境下进行,将每篇专利作为一项事务tk,其中tk={w1,w2,…,wi},wi是专利中第i个主题的词项,对应关联规则中的一个项目.在R语言中安装并加载arules和Matrix包,加载实验数据时将数据格式format设置为“basket”,将每一条专利记录看作是一个购物篮,专利主题词就是购物篮里的商品.使用apriori()函数进行关联规则挖掘,最小支持度阈值和最小置信度阈值分别为0.006和0.05,将最小规则长度minlen设置为2,避免规则中空项的出现.共生成规则552条,其中置信度、支持度和提升度最高的5条规则如表3~表5所示.在表中,lhs是英文left hand side的缩写,表示规则的前项,rhs是right hand side的缩写,表示规则的后项.通过对表3和表4进行分析,可以挖掘出以下规则:
| 图表编号 | XD00105121700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 艾楚涵、姜迪、吴建德 |
| 绘制单位 | 昆明理工大学知识产权发展研究院、昆明理工大学计算中心、昆明理工大学民航与航空学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}