《表1 重启前后变量的活跃值和相位变化》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
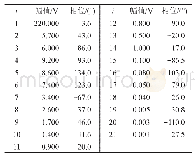
表2的第1列表示决策层次,从1开始计数,每确定一个决策变量,决策层次随之加1.表2的第2列表示重启前的变量赋值序列.“-x8”表示文字-x8被赋值为1;“x12”表示文字x12被赋值为1;“xi→xj”表示根据布尔约束传播,变量xi的赋值蕴涵出变量xj的赋值.决策层次为5时,变量x5的赋值存在冲突,此时相应增加学习子句中包含的变量的活跃值.当达到重启条件时,求解器撤销之前所有的变量赋值,表1的第3列和第5列分别表示重启后各个变量的活跃值和相位,此时重新选择变量活跃值最大的变量进行赋值传播.表2的第3列表示重启后的变量赋值序列.比较表1各个变量的活跃值,发现重启前后其变化不大,并且根据变量相位存储机制(即存储每个变量的赋值相位,若此变量在之前已经被赋值了,此时赋值保持不变,若未赋值,则一般默认赋值为False),各个变量的相位变化也不大.因此,从表2的第2列和第3列可以发现,重启前后第1层到第3层的决策变量是相同,即变量的赋值序列是相同的.分析其原因如下:(1)子句集规模大,其子句数和变元数甚至能达到百万级别,相应的变量的活跃值也较大,而每次冲突时,学习子句中包含变量的活跃值仅增加1;(2)频繁的重启导致产生的学习子句逐渐减少,且学习子句之间的相似度较高,学习子句中包含的变量不断地被奖励,有可能排序在前端的变量的活跃值越来越大,而那些活跃值小的但对求解过程起重要作用的变量将会被忽略.因此,频繁的重启产生重复变量赋值序列的可能性较大.从表2可以看出,子句集F在一次重启间隔之内的重复赋值序列为{-x8,x12,x2},决策层次分别为第1层、第2层和第3层.位于二叉树上层的决策变量很大程度上决定了搜索路径,因此不断产生的重复赋值序列导致求解器一直在相似的搜索空间内搜索,随着变量活跃值的不断累加以及周期性的衰减,变量的赋值顺序有可能会发生改变,此时,已耗费过多的计算资源.为了更直观地观察求解过程中此现象存在的普遍性,随机测试2015年SAT竞赛Application类型(1)Main track组的实例aaai10-planning-ipc5-pathways-13-step17.cnf.图1和图2分别表示使用不同的重启策略求解的过程中,每次重启时所产生的重复赋值序列.X轴表示重启次数,Y轴表示产生的重复赋值序列的大小.图1表示Luby重启策略产生的重复序列;图2表示Glucose3.0求解器中使用的动态重启策略所产生的重复赋值序列.不同的重启策略针对求解同一实例时,重启次数是不同的,Luby重启策略的重启次数为2639,动态重启策略的重启次数为10 564,由图1和图2可以看出,重启次数越频繁,产生的重复序列越多,并且其重复序列的值分布在一定的范围之内.
| 图表编号 | XD00102897500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 常文静、徐扬 |
| 绘制单位 | 西南交通大学信息科学与技术学院、系统可信性自动验证国家地方联合工程实验室、西南交通大学数学学院、系统可信性自动验证国家地方联合工程实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}