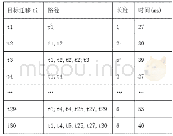
《表2 测试用例优先级排序算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
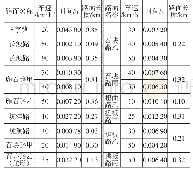
实验过程中,利用工具djUnit获得测试用例的覆盖信息.djUnit(5)可以为每个测试用例提供测试覆盖报告.通过解析测试覆盖报告便可获得每个测试用例覆盖类的信息(6).为了证明算法的有效性和稳定性,除了考虑文献[23]和[27]中提及的7种粗粒度的测试用例优先级排序算法外,也加入了基于附加分支覆盖的细粒度优先级排序算法与RA-TCP进行对比分析,并验证了排序效果与风险各项指标的相关性.8种对比算法的描述说明如表2所示.其中,T2算法为随机测试序列,这里取其50次独立实验的平均结果进行比较;T3算法是指在已知测试用例检测出的错误位置的情况下,将测试用例按照错误检测率最大的序列进行排序.然而,这个顺序是在实际预测过程中无法达到的,因此,本文将其作为各种排序方法有效性的上限.由于上述对比算法均非开源程序,故根据文献[23]和[27]的描述,对其进行仿真实现,获取实验结果.实验平台如下:3.7GHz CPU,12GB内存,1TB硬盘,Windows 8.1以及编译环境Eclipse 4.5.0.
| 图表编号 | XD00102888200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 于海、杨月、王莹、张伟、朱志良 |
| 绘制单位 | 东北大学软件学院、东北大学软件学院、东北大学软件学院、东北大学软件学院、东北大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}