《表1 主要模型参数设置:大数据挖掘在协议库存物资需求预测的研究和应用》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
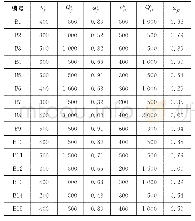
基于上述配网项目数据分析结果,本文协议库存需求计划采用随机森林算法进行预测。基于scikit-learn第三方机器学习库的实现,以所在地市、项目投资、项目类型、城市农村等4个因子作为输入因子,32个物资种类的纯出库数(出库数量-退库数量)作为输出因子,取训练样本的比例为80%.随机森林回归树的数量为100,叶子节点样本最少个数为30,以上数据作为预测模型的输入进行模型训练,在训练模型的过程中,不断反复调整模型参数,从多个参数组合中,确定了回归树的数量、节点最小样本数等参数的选取,作为需求预测模型最终参数。最后,根据下一年度的配网项目储备计划或年度综合计划,包括项目分类、下达项目投资金额、地市等变量,作为预测模型的输入数据,进行下一年度物料用量的需求预测。
| 图表编号 | XD00101339900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 陈国洪、刘烁、李燕燕、陈晔 |
| 绘制单位 | 国网福建省电力有限公司物资分公司、国网信通亿力科技有限责任公司、国网信通亿力科技有限责任公司、国网信通亿力科技有限责任公司 |
| 更多格式 | 高清、无水印(增值服务) |


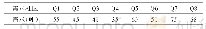


{kind=link}