《表2 5种算法混淆矩阵结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
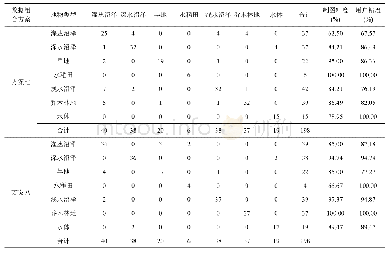
经过样本筛选、特征工程、特征降维后,本课题所用数据集的样本数共1 465条,其中,扩容小区样本110条,非扩容小区样本1 355条,98维特征。目标变量为是否扩容,其中,1表示扩容,0表示非扩容。本课题分别利用K近邻、逻辑斯特回归、决策树、随机森林、支持向量机分别对样本构建分类模型,通过比较准确率、混淆矩阵与ROC曲线,选择最佳分类模型。本课题采用Sklearn机器学习工具包实现上述5种分类算法,将数据集随机划分为训练集与测试集,训练集与测试集的比例为5:5。在测试集预测的结果如表2所示:
| 图表编号 | XD0080245900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.15 |
| 作者 | 钱兵、曹诗苑、王兵 |
| 绘制单位 | 中国电信北京研究院新兴信息技术研究所、中国电信北京研究院新兴信息技术研究所、中国电信集团有限公司网运部 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}