《表1 词向量关键词词集》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
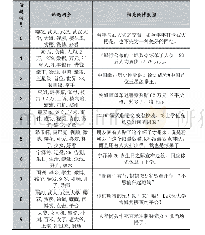
TF-IDF是一种常用的关键词提取方法,TF词频(Term Frequency)指的是某一个给定的词语在某文件中出现的次数,IDF逆文件频率(Inverse Document Frequency)指的是包含某一个给定词语的文档比例的倒数。一个词语的TF-IDF越大,表示该词语在某篇文章中出现次数越多,同时在其他文章中出现次数越少,则该词语就越能够代表某篇文章,该词语也就越能被界定为关键词[6]。但是TF-IDF算法只考虑了词语的词频,没有考虑词语的上下文关系,所以通过TF-IDF算法提取出的多个关键词之间的语义关系、相关程度等信息都无法解释,相应的内容态势感知结果的解释性也就很差。为了解决这个问题,先通过TF-IDF算法对基准语料库提取关键词,将提取出的关键词作为种子关键词,然后从Word2vec词向量空间中根据余弦距离度量提取出较近的一组词语作为一个关键词词集。本实验中,基于维基百科中文语料的词向量模型和密码产品语料的词向量模型提取出的种子关键词和关键词词集如表1所示。
| 图表编号 | XD0077401200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.10 |
| 作者 | 魏忠、周俊、石元兵、黄明浩 |
| 绘制单位 | 卫士通信息产业股份有限公司、卫士通信息产业股份有限公司、卫士通信息产业股份有限公司、卫士通信息产业股份有限公司 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}