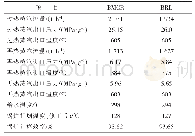
《表1 主要设计参数配对表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
需要说明的是,匹配循环次数也对算法效率产生影响。由于匹配循环次数等于[(实时图宽度-模板图宽度)/线程块Y方向大小,(实时图长度-模板图长度) /线程块X方向大小],匹配循环次数越少,CUDA内核函数1次可使用核心数越多,算法开销也越小。当内核函数计算需被拆分成多次,无法一次完成时,加速效果将大大降低。以上性能加速均基于线程块大小的平方与匹配循环次数的乘积小于GPU设备标称核心数目。实验使用的GPU单个线程块block管理的最大线程数量为1024,BLOCKSIZE必须小于等于32。固定模板图为64像素×64像素,模板图线程块大小BLOCKSIZE可从典型值8、16、32中取一种;固定模板图为32像素×32像素,模板图线程块大小BLOCKSIZE可从典型值8、16中取一种。又鉴于实验所用GPU设备标称核心数目,线程块大小、匹配循环次数最好按表1所列配对方式选取,具体的实验结果参见下一部分内容。
| 图表编号 | XD0060111600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.28 |
| 作者 | 崔文、李强、刘晓春、李由 |
| 绘制单位 | 中国人民解放军96941部队、中国人民解放军96941部队、国防科技大学空天科学学院、中国航天员科研训练中心人因工程重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}