《表1 金矿数据:耦合PCA-SVM算法的金矿矿床规模预测分析研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《耦合PCA-SVM算法的金矿矿床规模预测分析研究》
选取甘肃北山区域的具有时空分布特征的地球化学采样点多样本均值训练集数据结构,如表1所示。在北山区域经过勘查、分析,建立预测靶区,对靶区进行钻探,发现矿床存在则判定为有矿,其余划定为无矿。训练集中总共7个类别的矿床规模数据,每类数据均有35维变量,数据条目共3 813条。其中35维变量中的前34维为单位体积内Ag、Au、As、Cu、F等元素的质量以及氧化物和氟化物的质量,第35维为矿床规模类型。每个类别的矿床规模数据中均随机选择72%作为训练集,18%作为验证集,10%作为测试集,训练集、验证集和测试集数据均不相交。因为数据集中特大型矿床和大型矿床的数据个数相对较小,所以为了减小因为数据量不均衡带来的误差,将特大型矿床及大型矿床归入中型矿床。
| 图表编号 | XD0056960000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.01 |
| 作者 | 刘承照、韩帅、李明超、朱月琴 |
| 绘制单位 | 天津大学水利工程仿真与安全国家重点实验室、天津大学水利工程仿真与安全国家重点实验室、天津大学水利工程仿真与安全国家重点实验室、中国地质调查局发展研究中心、自然资源部地质信息技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
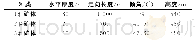
![表6 矿床与典型碲化物型金矿[27-29]对比](http://bookimg.mtoou.info/tubiao/gif/KCYD202006005_08700.gif)



{kind=link}