《表4 Hermann等[19]文献中CNN/DM数据规模》
![《表4 Hermann等[19]文献中CNN/DM数据规模》](http://bookimg.mtoou.info/tubiao/gif/MESS201905001_06200.gif) 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
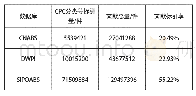
与Gigaword和部分DUC/TAC数据集只包含单句话的摘要不同,CNN/Daily Mail(简称CNN/DM)作为单文本摘要语料库,每篇摘要包含多个摘要句。CNN/DM最初是Hermann等[19]发布的机器阅读理解语料库。作者从美国有线新闻网(CNN)(1)和每日邮报网(Daily Mail)(2)中收集了约100万条新闻数据作为机器阅读理解语料库。在CNN和Daily Mail的新闻数据中,每篇新闻包括一条或者多条人工要点,将隐藏一个命名实体的要点作为填空题的问题,将新闻内容作为回答填空题的阅读文字。表4是语料库的详细统计信息。
| 图表编号 | XD0054896100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 侯圣峦、张书涵、费超群 |
| 绘制单位 | 中国科学院计算技术研究所智能信息处理重点实验室、中国科学院大学、中国科学院计算技术研究所智能信息处理重点实验室、中国科学院大学、中国科学院计算技术研究所智能信息处理重点实验室、中国科学院大学 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}