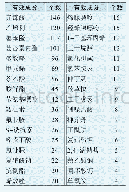
《表1 样本种类及对应个数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在临床应用上,医生希望得到腭裂语音高鼻音的等级(正常、轻度、中度、重度)。而目前的国内外研究主要局限于对高鼻音有无的判别,其一个原因是缺少标准的腭裂语音数据库。本实验采用的语音数据来自于四川大学华西口腔医院唇腭裂外科,数据按照“四川大学华西口腔医院语音矫治室普通话构音测量表”进行录制。该表充分考虑了普通话构音结构和腭裂语音的特性,分别有含元音/a/、/i/、/u/的词语各21个共63个,例如“爸爸”“鼻子”“布鞋”等词。语音数据由专业的言语治疗师进行判听,并为其人工划分高鼻音等级(四类)作为“金标准”。本实验一共采用56名儿童的语音数据,正常、轻度高鼻音、中度高鼻音、重度高鼻音儿童各14位,总共3 086个语音数据,具体包含的词语类别及高鼻音程度对应的个数如表1。
| 图表编号 | XD0053255100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.15 |
| 作者 | 付方玲、何飞、付佳、尹恒、黄华、何凌 |
| 绘制单位 | 四川大学电气信息学院、四川大学电气信息学院、四川大学电气信息学院、四川大学华西口腔医院、四川大学电气信息学院、四川大学电气信息学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}