《表2“属性-值”对生成的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
研究得到的分别在“属性”与“值”上单独评估的结果见表3。表3中,Attributes表示研究只对生成的“属性”进行评测,values表示只对生成的值进行评测,这些值对应的属性都是预测正确的。atn表示注意力机制,copy表示拷贝机制,A表示属性,V表示值。除了基本的S2S模型外,其它带有注意力机制或者拷贝机制的模型在“属性”与“值”上的结果都要好于基于流水线的方法。经过分析可知,注意力机制在“属性”与“值”的生成上都带来提升,分别是从69.9到73.3以及从30.9到52.7。实验结果表明注意力机制对提升模型的准确率是很有帮助的。拷贝机制在“属性”生成上带来的提升比较有限(从73.3到74.2),在“值”的生成上带来的提升比较显著(从52.7到76.4)。这是由于“属性”与“值”不同,而且常常不会出现在文本表述中。通过观测数据,研究发现不带有拷贝机制的Seq2Seq模型只能生成特殊符号UNK来表示OOV的词,而带有拷贝机制的模型可以从文本中拷贝内容来生成稀有词。此外,目标词表中只包含“属性”的S2S+atn模型在“属性”生成上取得了最好的结果。
| 图表编号 | XD0050504600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 鲍军威、周明、赵铁军 |
| 绘制单位 | 哈尔滨工业大学计算机科学与技术学院、微软亚洲研究院、哈尔滨工业大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




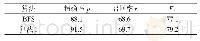
{kind=link}