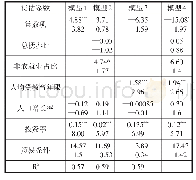
《表2 2002—2008年样本模型估计结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《人口红利与中国经济增长:基于人口结构和质量的分析》
注:每个单元格第一个数字为系数估计值,第二个数字为对应的T值;***、**、*分别表示该系数在1%、5%和10%显著性水平下异于0
先看2002—2008年第一个子样本的实证结果。在模型估计中,先估计了只有控制变量的经济增长模型,然后分别加入人口结构和人口质量两组核心变量,最后同时加入两组变量,形成四个回归模型。由于模型的因变量和部分自变量包括投资率和贸易条件属于同期实现的内生变量,模型存在内生性问题。为更准确地估计参数,采用了两阶段广义矩估计方法(two step GMM),工具变量由因变量的滞后项组成。四个模型的估计结果如表2所示。
| 图表编号 | XD0026437100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.08.20 |
| 作者 | 徐诺金 |
| 绘制单位 | 中国新供给经济学50人论坛 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}