《表3 SVM二分类结果评价》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《学术文本词汇功能识别——在关键词自动抽取中的应用》
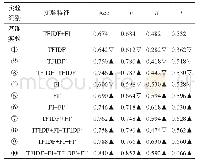
注:▲表示得分高于基准实验得分,▽表示得分低于基准实验得分。
鉴于每篇文献的作者关键词约为4.09个,本文选择n=5时的P@n和NDCG@n以及MAP对基于排序的抽取结果进行了评价,评价结果如表4所示。从表4可以发现,除了实验(1)、实验(4)和实验(5)外,其他实验组相较于基准实验在三个指标上都有明显的提升,其中效果最好的实验(10)在MAP、NDCG@5和P@5上依次达到0.813、0.828和0.447,相对提升高达168.32%、189.50%和148.30%。提升效果最弱的实验(2)也达到0.490、0.500和0.300,相对提升61.72%、74.83%和66.67%。这些结果充分说明,在基于排序的关键词自动抽取中,词汇功能特征具有积极的作用。
| 图表编号 | XD00206683000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.24 |
| 作者 | 姜艺、黄永、夏义堃、李鹏程、陆伟 |
| 绘制单位 | 武汉大学信息管理学院、武汉大学信息检索与知识挖掘研究所、武汉大学信息管理学院、武汉大学信息检索与知识挖掘研究所、武汉大学信息资源研究中心、武汉大学信息管理学院、武汉大学信息检索与知识挖掘研究所、武汉大学信息管理学院、武汉大学信息检索与知识挖掘研究所 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}