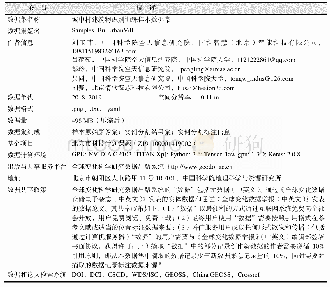
《表4 215个样本(占现实总量的50%)训练下震泽古镇历史建筑的识别结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《历史建筑智能识别可行性研究——运用正射影像和数字图像检测技术的江南水乡古镇实验》
注:增加90个样本,召回率提高15%,精确度提高4.5%。
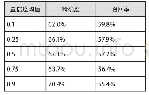
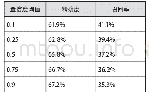
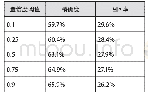
学习样本数量的多少同时关联识别的正确性和时间效率。为了确定最有效的学习样本量,测试模型选取了66、125和215个三组学习样本进行训练,分别覆盖了震泽古镇测试区现状历史建筑的15%、30%和50%。将上述三组学习样本分别放入Faster R-cnn模型中进行训练,获得三组不同参数的识别模型。当模型获得历史建筑识别结果后,再根据公式(4)和公式(5),分别统计计算三组数据在置信度阈值为0.1、0.25、0.5、0.75及0.9时,模型在精确度和召回率上的表现,如表2-表4所示:
| 图表编号 | XD00199976300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.05 |
| 作者 | 周俭、叶振、俞文彬、宋俊锋、李燕宁 |
| 绘制单位 | 上海同济城市规划设计研究院有限公司 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}