《表1 钻探地质描述:基于网络爬虫的搜索引擎的设计与实现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
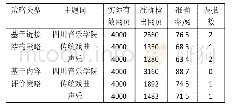
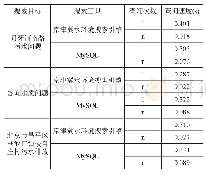
首先定义爬虫名称,爬取的域名和起始页面。其次,获取网页列表页URL,下载后使用parse函数处理,同时定理next_url来循环爬取其他URL。然后在详情页面上具有大部分的目标信息,针对这些信息,使用CSS和XPATH选择器提取页面详细信息。部分字段提取样式如表1:
| 图表编号 | XD00187165800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.25 |
| 作者 | 高文超、李浩源、徐永康 |
| 绘制单位 | 中国矿业大学(北京)机电与信息工程学院、中国矿业大学(北京)机电与信息工程学院、中国矿业大学(北京)机电与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}