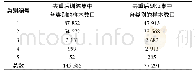
《表3 去重后码字对比:面向无载体信息隐藏的映射关系智能搜索方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
此外,重复码字的碰撞现象导致搜索的难度也逐渐增加,表3展示了每种方法在不同规模的图像库中获得的可用码字数目。从表3中可以看出LDA+DCT方法在100张图片时可以产生56个码字。但是当图像库增长到200张时变为96个码字,只增长了40个,证明了新加入的100张图像产生的100个码字中有60个与已有的相同产生碰撞。另外在Pixel方法中,图像数量从100增加至150时,新增码字数为20;图像数量再增加50总数达到200张时,新增码字数为18;图像数量再增加56,总数达到256张时,新增码字数目只有13。图像每增加50张,产生可利用的码字越来越少。这也证明了传统方法中为了构建一个完备的图像库需要搜索2倍甚至几倍于码字数目的图像,并且随着已知码字越来越多,搜索的难度将逐渐增大。
| 图表编号 | XD00174278600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 王亚宁、吴槟 |
| 绘制单位 | 中国科学院信息工程研究所信息安全国家重点实验室、中国科学院大学网络空间安全学院、中国科学院信息工程研究所信息安全国家重点实验室、中国科学院大学网络空间安全学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}