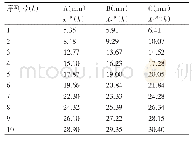
《表1 实验数据集:HDVM:基于关系矩阵的关联数据压缩查询模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
下载链接:CN2012(https://datahub.io/dataset/combined-nomenclature-2012)Dog Food(https://datahub.io/dataset/scholarlydata)Archive Hub(https://datahub.io/dataset/archiveshub-linkeddata)Jamendo(https://datahub.io/dataset/jamendo-dbtune)Linked Mdb (http
为了验证HDVM模型的有效性,本文对表1中的数据集进行了构建压缩查询模型的实验.实验数据集按从小到大排序,其中谓语数量表示关联数据集中出现的谓语总个数,谓语簇数量是指关联数据集中所有不相同的谓语簇的数量.从后续实验结果中得知,内存压缩模型最终的压缩率和查询效率与实验数据集的谓语簇数量具有一定关系,谓语簇的数量是衡量HDVM在一个关联数据集上实验效果优劣的重要指标.
| 图表编号 | XD0017144000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.03.01 |
| 作者 | 符海东、彭燊、黄莉、顾进广 |
| 绘制单位 | 武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室、武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室、国家新闻广电出版总局富媒体数字出版内容组织与知识服务重点实验室、武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室、武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室、国家新闻广电出版总局富媒体数字出版内容组织与知识服务重点实验室、湖北语言与智能信息处理研究基地(武汉大学) |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}