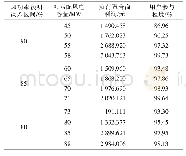
《表4 各簇高频区间内硅含量可匹配样本数统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于k-means++的高炉铁水硅含量数据优选方法》
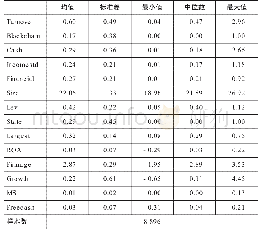
首先确定各样本所属的簇,以该簇的“高频区间”作为标准,遵循“不在先行周期内选择,不重复选择”的原则,优选每个样本对应的硅含量值。经统计,在1478个硅含量值中,共有731个值处于高频区间中,为去异常后的735个样本匹配硅含量,统计结果如表4所示,由表可知ClusterD中样本可完全实现匹配。
| 图表编号 | XD00159126900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 尹林子、关羽吟、蒋朝辉、许雪梅 |
| 绘制单位 | 中南大学物理与电子学院、中南大学物理与电子学院、中南大学自动化学院、中南大学物理与电子学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}