《表1 二元逻辑回归分类表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
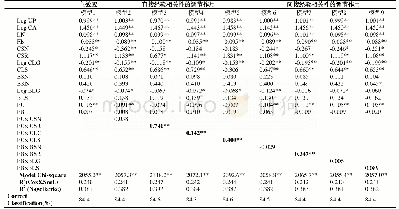
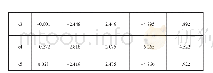
在8 339份有效样本中,属于1、2、3、4、5、6、7、8、9、10分满意度水平的样本数量分别是420、300、507、545、1 626、1 286、1 161、1 266、382、846份。将300份2分满意度水平的样本(类标值“1”)与382份9分满意度水平的样本(类标值“2”)作为因变量,上述16个自变量组成样本数据集,采用IBM SPSS Statistics 19/二元逻辑回归/Wald方法寻找养老保障满意度影响因素,结果得到分类表(见表1)。表1显示,步骤4得到的整体回归分类正确率最高,为77.0%,但对类标值1的预测偏低。步骤5得到的整体回归分类正确率次之,为76.8%,对类标值1的预测准确率高于步骤4与步骤6的预测水平。步骤6得到的整体回归分类正确率偏低,仅75.8%;且对类标值1的预测也偏低。因此,我们将步骤5得到的自变量(受教育程度;受教育满意度;家庭经济状况满意度;总体生活满意度;对社会总体评价)用于本文的建模。各变量的赋值与描述性统计如表2所示。
| 图表编号 | XD00125730400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.20 |
| 作者 | 李熠煜、禹宁瑶 |
| 绘制单位 | 湘潭大学公共管理学院、湘潭大学公共管理学院、湖南科技大学人文学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}