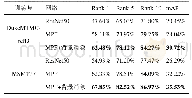
《表4 跨数据库实验对比(识别率)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
从表4中可以看出,由于CK+的数据多为欧美人而JAFFE的数据为亚洲人,CK+上训练好的模型在JAFFE上的表现并不理想,但基于改进StarGAN的数据增强方法比传统方法的跨数据库识别率更高,这说明了本文方法能在一定程度上提高模型的泛化能力。传统方法更多的是通过模拟多种场景来提高模型的泛化能力。而本文方法是从语义层次上扩大数据量,从而使得模型更关注语义特征。
| 图表编号 | XD00119704700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.15 |
| 作者 | 孙晓、丁小龙 |
| 绘制单位 | 合肥工业大学情感计算与系统结构研究所、合肥工业大学计算机与信息学院、合肥工业大学情感计算与系统结构研究所、合肥工业大学计算机与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}