《表1 训练集总结:基于迁移学习的MHC-I型抗原表位呈递预测》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
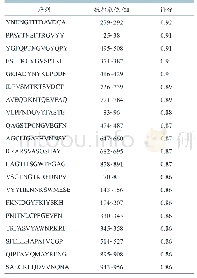
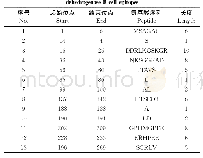
预训练模型用到的阳性集来源于Pearson等[21]和Bassani-Sternberg等[22]产生的数据以及SysteMHC质谱多肽数据库[23]。将这些数据集合幵后,剔除长度小于8以及大于14的多肽,然后根据多肽和HLA分型去重,总共得到接近16万的多肽数据(表1)。阴性集来源于人类蛋白组的随机切割的多肽(剔除出现在阳性数据集中的多肽),从中挑取与阳性集等量的阴性多肽与阳性集合幵构成训练集,然后从训练集中各挑取5000条阳性多肽和5000条阴性多肽构成验证集。
| 图表编号 | XD00113076700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 胡伟澎、李佑平、张秀清 |
| 绘制单位 | 华南理工大学生物科学与工程学院、深圳华大生命科学研究院、华大吉诺因、深圳华大生命科学研究院、华大吉诺因、中国科学院大学华大教育中心、深圳华大生命科学研究院、华大吉诺因、中国科学院大学华大教育中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}