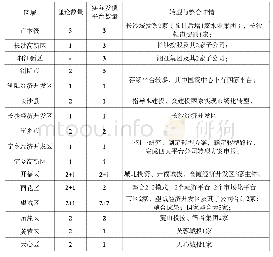
《表1 各区馆加入联合采编平台时间》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《联合书目数据库重复书目数据控制工作实践研究——以深圳“图书馆之城”为例》
注:大鹏新区未成立区馆除外,数据量太小,仍然按批接入
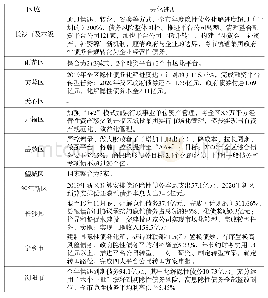
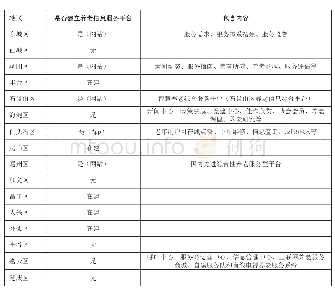
按照《美国图书馆学会词汇》的定义,联合编目是指“一组各自独立的图书馆开展的书目原始编目的协作活动,成员馆之间有义务相互提供书目记录”。联合编目可以降低成员馆的编目成本,提高编目工作质量,避免书目数据资源的重复建设。2014年,深圳“图书馆之城”召开馆长联席会议,提出搭建“图书馆之城”联合采编平台,将成员馆的书目数据、采访数据与馆藏数据等整合起来,按照统一模式实施数据的加工、构建和运行管理,要求各成员馆在统一平台上开展联合采编工作。2015年,深圳“图书馆之城”联合采编平台搭建完成,自同年6月深圳大学城图书馆首批接入平台,截至2018年底,深圳“图书馆之城”联合采编平台已经整合了包括深圳图书馆、深圳大学城图书馆(深圳市科技图书馆)等9个区馆、11个成员馆的书目数据(如表1)。中央书目库中书目数据已有近300万条,中文书目数据278万条,占整个中央书目库书目数据总量的92%,这其中又以中文图书书目数据占绝大部分。因此,中文图书书目数据质量的控制工作是深圳“图书馆之城”书目质量管理工作的重中之重,联合采编平台的建立是书目质量控制工作得以开展的基础保障,取消了原有数据批接收模式,按系统权限进行分级控制,建立多种有效机制,堵住了重复数据产生的主要源头。
| 图表编号 | XD00112087000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.30 |
| 作者 | 陈娟 |
| 绘制单位 | 深圳图书馆 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}