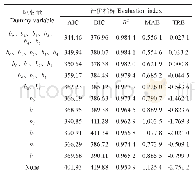
《表1 哑变量赋值形式:横断面研究护理论文评价要点解读(三)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
具体描述内容,建议“主要结果”:(1)研究结果的有效性通常取决于对重要混杂变量的控制,因此应全面了解并对混杂变量进行精确测量,在多因素统计学模型中进行校正。(2)作者应对所有关注的、潜在混杂变量进行解释,并说明在统计模型中纳入或排除变量的标准,还需要阐明对哪些混杂变量进行了调整,以及选择这些混杂变量的原因。例如作者冯佩笑等[38]发表的论文《产钳助产术后尿潴留发生情况及其影响因素分析》中,采用Logistic多元回归分析显示:第一产程时间延长及产后2h出血量多为产钳助产术后发生尿潴留的独立危险因素,但在进入模型前,作者首先进行了单因素变量的筛选,共有6个变量(第一产程时间、总产程时间、产后2h出血量、产后24h出血量、产后血蛋白减少量、产前导尿次数)具有统计学意义(均P<0.05),未发现年龄、产次具有统计学意义,但结合临床意义考虑这两个因素是较确切的影响因素,因此同时纳入多因素的模型进行分析,以便校正混杂的因素。并应分别报告所关注的研究因素在校正混杂前后的结果及精度(如95%可信区间),即单因素分析(建议采用简单回归分析)和多因素分析模型。(3)采用多变量分析方法时应符合研究的目的和数据的类型。如自变量(暴露):在多重线性回归或logistic回归中,连续变量(如年龄)、有序分类变量(如文化程度)和无序分类变量(如种族类别)都可以作为回归模型的自变量;因变量(结局):如果是连续型变量,常可选用线性回归分析模型;如果是分类变量,常选用logistic回归分析模型。(4)连续型变量(定量数据),如定量测量的结局(因变量)、暴露(自变量)、混杂变量等。具体包括以下情形:若将自变量(暴露)直接作为连续性变量处理,应该考虑自变量(暴露)与因变量(结局)关联的潜在机制,不能简单地将其认定为线性关联进行处理,还应考虑和讨论非线性关联的可能性;若考虑对连续性暴露变量进行分组处理,生成一个新的分类变量,由于是否分组、如何分组可能对后续分析产生重要影响,此时需要作者对分组原因、分组方式做出解释,如分组的个数、截断值、各组均值或中位数等[36]。建议对研究主要关注的定量暴露变量,同时探索其被视作连续型变量和分组变量,哪个结果更有意义。(5)应注明研究变量的赋值情况,以便统计分析,主要用于回归分析时。例如二分类变量一般采用0和1赋值,例如吸烟:1,非吸烟:0;男:1,女:0等。分类变量可以给出参照组并指出各类别的赋值,如:文化程度:初中=1(参照),高中=2,大学=3;此时将计算高中与初中优势之比,大学与初中优势之比。对于无序多分类变量或间距大多数的有序分类变量,均应按哑变量对待。例如职业:农民,事业职员,企业工人,以商业人员作为参照水平,哑变量X1(农民)=0,X2(事业职员)=0,X3(企业工人)=0(见表1),这样关于这类变量的优势比就是每个哑变量和参照水平优势之比。一般赋值较小的水平常被作为参照水平[29]。(6)应依据结局(结果)的类型,选择符合数据分析的统计学方法,在分析横断面调查研究数据时,经常使用多重线性回归或logistic回归等统计学模型计算多个自变量(暴露)与疾病(结局)的关联。除了报告多重线性回归系数与其95%置信区间,以了解该变量的精度,同时还应报告方程的决定系数与调整决定系数,其是反映线性回归模型能在多大程度上解释因变量的变异;logistic回归应报告危险度比值比OR值及95%置信区间,以了解该自变量的精度。(7)在进行统计推断时,应对结果进行量化,并采用能反映测量误差和不确定性的指标(如95%置信区间),而非假设检验(仅用P值),因为效应量及其95%置信区间能提供更多有价值的信息[39]。因此,需要报告结果的主要指标检验的确切P值(而仅仅非大于或小于某界值)和或置信区间[4]。
| 图表编号 | XD00107721000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 刘晓华、周倩、成守珍 |
| 绘制单位 | 中山大学附属第一医院现代临床护理编辑部、中山大学附属第一医院临床研究中心、中山大学附属第一医院护理部 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}