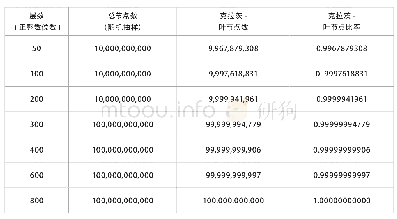
《表1 不同随机失活比率的准确率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《混合Gabor的轻量级卷积神经网络的验证码识别研究》
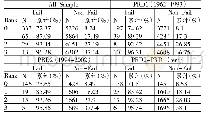
为了防止出现过拟合现象,本文在模型训练时加入了Dropout层进行调节,还对不同学习率和批量大小进行了对比实验。通过表1的对比实验可知,设置不同大小的随机失活比率,对模型的准确率存在影响。当Dropout为0.3时,整个网络的性能最佳。如果随机失活的值较小,则仍然会出现过拟合现象,无法使得模型具有较好的鲁棒性。通过表2可以发现,当初始学习率较大时,模型梯度下降的速度较快,整个网络呈现震荡趋势,难以找到最优解,因此识别准确率较低。当初始参数量设置较低时,模型训练时间较长,且容易陷入局部最优解中,识别准确率也较低。当初始学习率在0.01时,整个模型的训练时间和效果达到最优。通过表3可知,每次训练的批量大小不同时,模型的准确率也存在差异。当批量较小时,模型训练时间较慢,而当批量大小为50时,对计算机硬件配置要求较高,无法平稳地训练。因此,本文随机失活概率设计为0.3,初始学习率为0.01,批量大小为10,此时模型达到最优。
| 图表编号 | XD00175835100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.10 |
| 作者 | 刘静、张学谦、刘全明 |
| 绘制单位 | 公安部第三研究所、四川省公安厅网络安全保卫总队、山西大学计算机与信息技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}