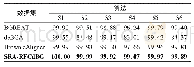
《表3 模拟数据集上正确对准百分比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《通过区域筛选和简洁de Bruijn图比对高重复短序列》
从表3可见,对于6种模拟数据集,与其他3种算法相比,本文算法SRA-RFCdBG均获得最高的正确对准百分比.这是由于SRA-RFCdBG算法采用的区域选择方法进行筛选候选位置时考虑了空格符号对比对的影响,这样可以减少序列与参考基因组比对的候选位置个数.此外,Illumina平台产生的序列存在的主要错误类型为“替换”,但也存在“插入和删除(indel)”错误.SRA-RFCdBG算法通过同时对这两种类型错误的处理,提高了种子命中率,从而获得更高的正确对准百分比.从表4也看到:每种算法在人类基因组数据集(S3,S4)上的正确对准百分比都低于其他4个数据集(S1,S2,S5,S6)上的正确对准百分比.这是由于人类基因组(S3,S4)中碱基序列重复率较高,导致算法将S3、S4数据集中序列与参考基因组比对时,获得正确对准的百分比较低.
| 图表编号 | XD00157821100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 黎瑶、钟诚 |
| 绘制单位 | 广西大学计算机与电子信息学院广西高校并行分布式计算技术重点实验室、广西大学计算机与电子信息学院广西高校并行分布式计算技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}