《表1 真实数据集详细配置》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
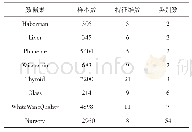
该节从实验对比的角度来突出本文所提算法的实际分类性能。在构建对抗的SVM(A-SVM)过程中以线性型SVM(Linear-SVM)为基础。对比算法选择如下:线性型SVM[15],其参数惩罚系数C搜索范围为{10-5,10-4,…,104,105};高斯型SVM(Gaussian-SV M)[15],其参数惩罚系数C搜索范围为{10-5,10-4,…,104,105},高斯核函数中核宽度δ搜索范围为{10-5,10-4,…,104,105};随机森林(Random Forest,RF)[16],其叶子节点数设定为文章[17]中的推荐值,即T=27;k近邻算法(k nearest neighbor,kNN)[18],其近邻个数搜索范围为{1,2,3,…,30};决策树(C4.5)算法[19]以及朴素贝叶斯(na觙ve Bayes,NB)[20],其参数设置均采用默认值。实验中选取的真实数据集来源于UCI machine learning repository[21]和the KEEL-dataset repository[22]。表1详细列出了所选真实数据集的详细配置。实验中所有算法的最优参数均经网格搜索结合十折交叉验证的方法获得[5]。所有实验结果均在matlab 2015b软件平台上运行程序获得,电脑配置为64位的windows10操作系统,CPU为Inter(R)Core(TM)i7-4790,CPU主频为3.6GHz,内存大小为8G。
| 图表编号 | XD00102860400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.28 |
| 作者 | 陆兵、顾苏杭 |
| 绘制单位 | 常州轻工职业技术学院信息工程与技术学院、常州轻工职业技术学院信息工程与技术学院、江南大学数字媒体学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}