《表7 与时域、频域输入试验结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
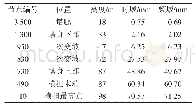
整体精度和误差如表6和表7所示,输入变量L代表响度,变量R代表粗糙度,变量J代表尖锐度,变量A代表计权声压级。CNN模型的听觉谱输入训练精度为97.53%,测试精度96.31%,与试验的对照模型BP神经网络评价模型相比,精度最多提高4.73%;与CNN评价模型的时域、频域输入试验结果相比测试精度高出4.06%。从CNN模型使用L、R、J、A单一输入试验结果中,不难看出使用心理声学参数输入对于声品质预测精度没有明显优势。从结果中可以看出卷积神经网络具有强大的自动特征提取和表达能力,在输入时频信息较全的样本时可准确地表达样本特征,实现较好的分类预测,同时由于卷积操作具有样本信号表达特征的稀疏性、连接权值共享性等特点,有效降低了训练的复杂度。
| 图表编号 | XD0038623500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.15 |
| 作者 | 梁凯、赵海军、宋伟志 |
| 绘制单位 | 洛阳理工学院信息化技术中心、洛阳理工学院信息化技术中心、天津职业技术师范大学汽车与交通学院、洛阳理工学院信息化技术中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}