《表2 楼层数据:基于Scrapy和Solr的社交网络兴趣度分析原型系统》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Scrapy和Solr的社交网络兴趣度分析原型系统》
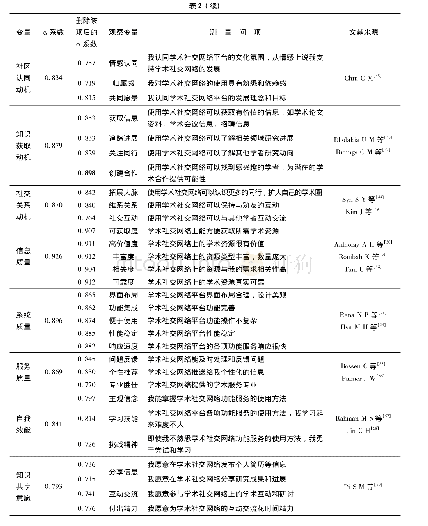
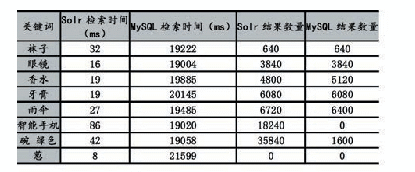
在使用爬虫时,可以使用“http://tieba.baidu.com/f?fr=ala0&kw=贴吧名称”作为种子URL对贴吧数据进行爬取。通过对DOM进行分析:在主题列表中,主题的大部分数据以JSON数据格式存放在每一行li标签的data-field属性中;在主题详细内容页面中,每一楼层的大部分数据以JSON数据格式存放在div标签的datafield属性中。如表1和表2所示,在Scrapy中可使用XPATH表达式从HTML源代码中提取出JSON并解析出数据供后期分析使用。用类似的方式也可以分析并提取出分页链接URL以获取更多数据。
| 图表编号 | XD0015596000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.04.18 |
| 作者 | 顾韫琪、沈健、龚旻、秦韵淇 |
| 绘制单位 | 常熟理工学院计算机科学与工程学院、常熟理工学院信息化办公室、常熟理工学院计算机科学与工程学院、常熟理工学院计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}